Transformer
1. Transformer 的本质
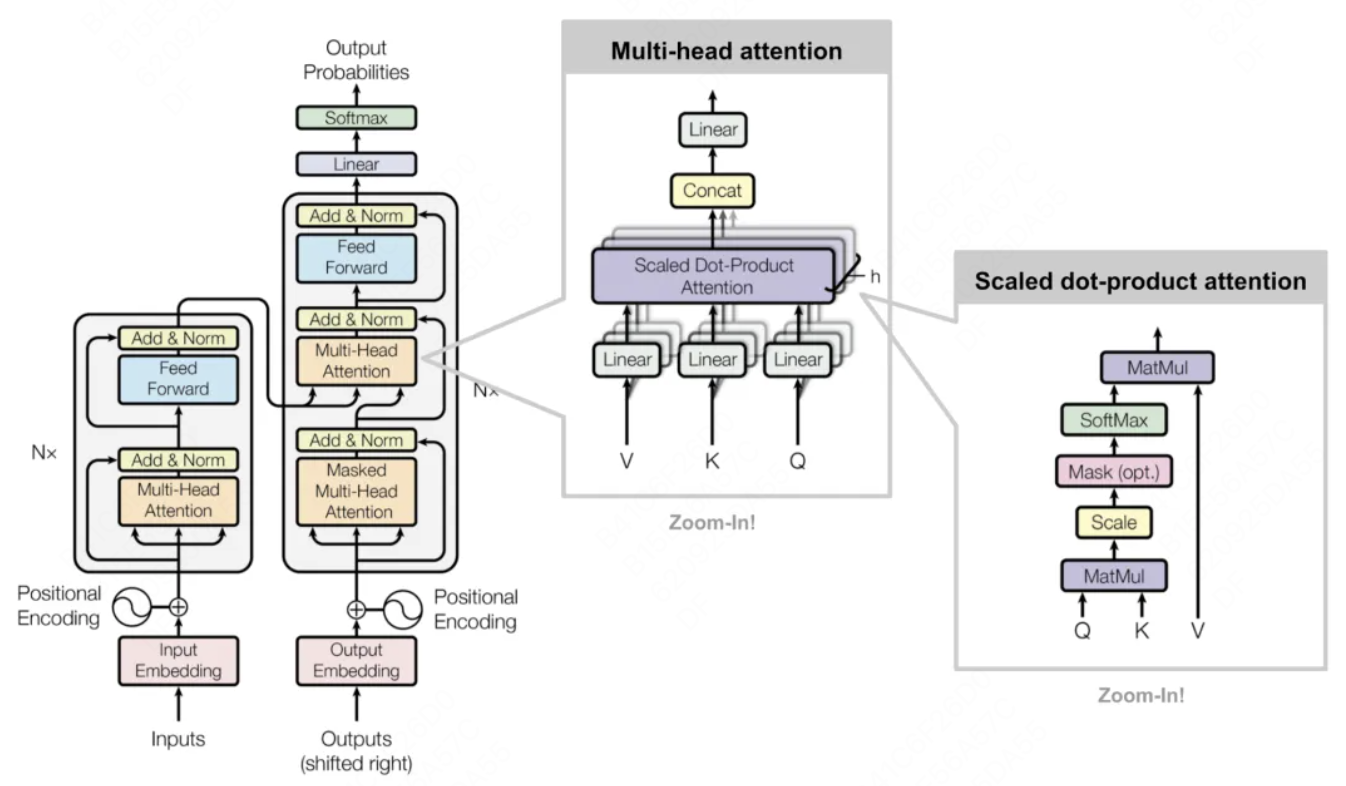
Transformer 架构:主要由输入部分(输入输出嵌入与位置编码)、多层编码器、多层解码器以及输出部分(输出线性层与 Softmax)四大部分组成。
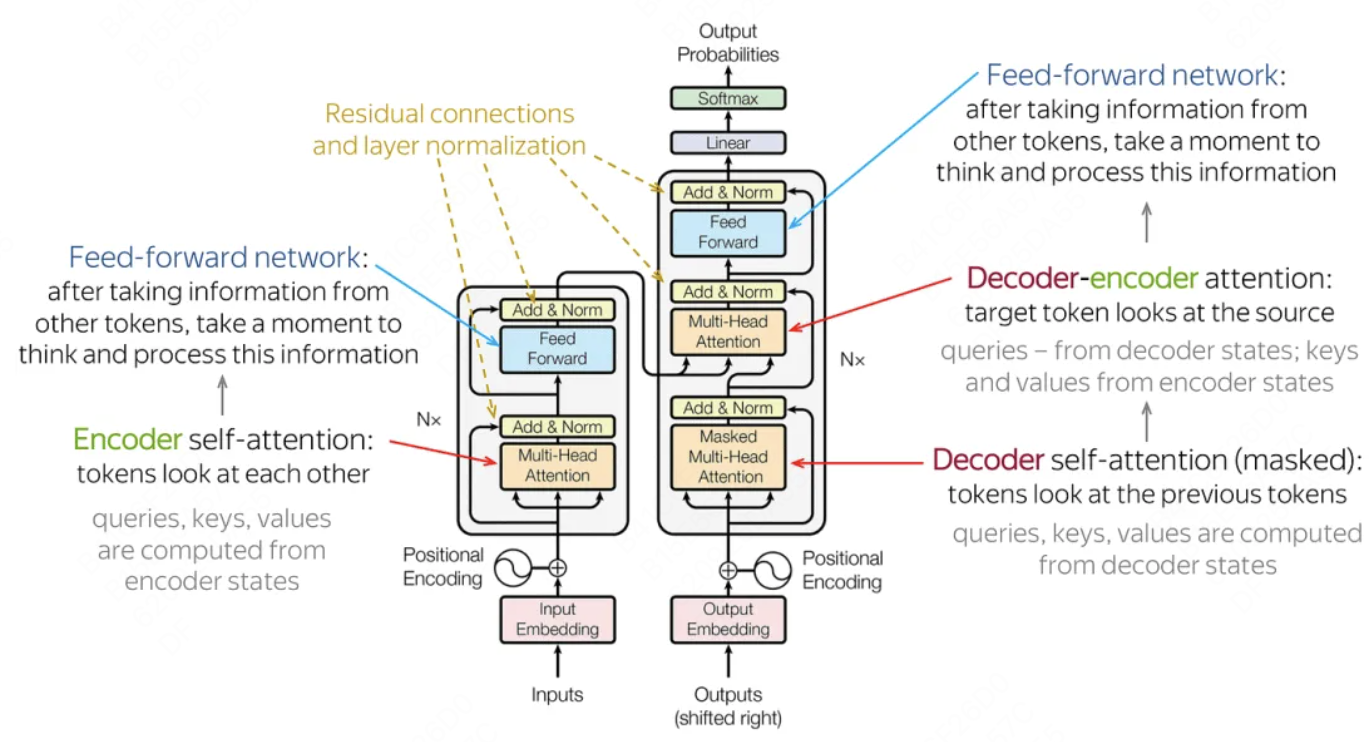
- 输入部分:
- 源文本嵌入层:将源文本中的词汇数字表示转换为向量表示,捕捉词汇间的关系。
- 位置编码器:为输入序列的每个位置生成位置向量,以便模型能够理解序列中的位置信息。
- 目标文本嵌入层(在解码器中使用):将目标文本中的词汇数字表示转换为向量表示。
- 编码器部分:
- 由 N 个编码器层堆叠而成。
- 每个编码器层由两个子层连接结构组成:第一个子层是一个多头自注意力子层,第二个子层是一个前馈全连接子层。每个子层后都接有一个规范化层和一个残差连接。
- 解码器部分:
- 由 N 个解码器层堆叠而成。
- 每个解码器层由三个子层连接结构组成:第一个子层是一个带掩码的多头自注意力子层,第二个子层是一个多头注意力子层(编码器到解码器),第三个子层是一个前馈全连接子层。每个子层后都接有一个规范化层和一个残差连接。
- 输出部分:
- 线性层:将解码器输出的向量转换为最终的输出维度。
- Softmax 层:将线性层的输出转换为概率分布,以便进行最终的预测。
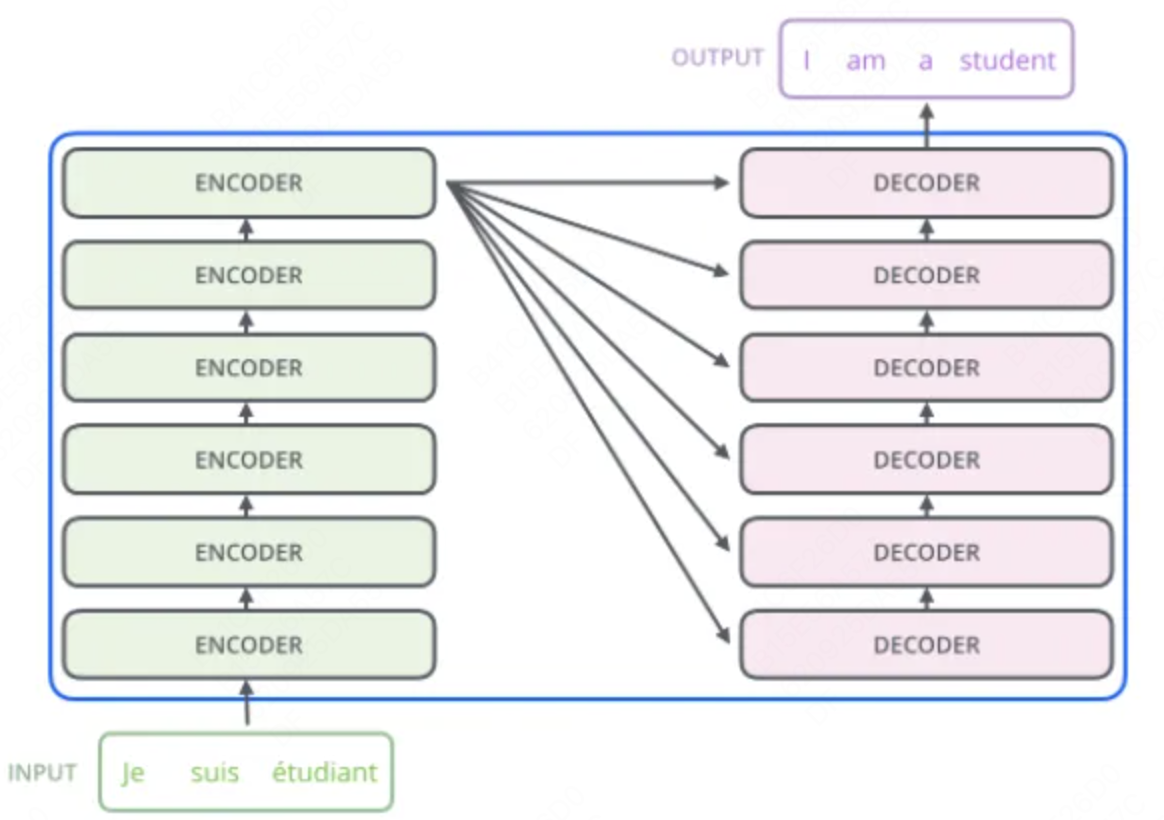
Encoder-Decoder(编码器-解码器):左边是 N 个编码器,右边是 N 个解码器,Transformer 中的N 为 6。
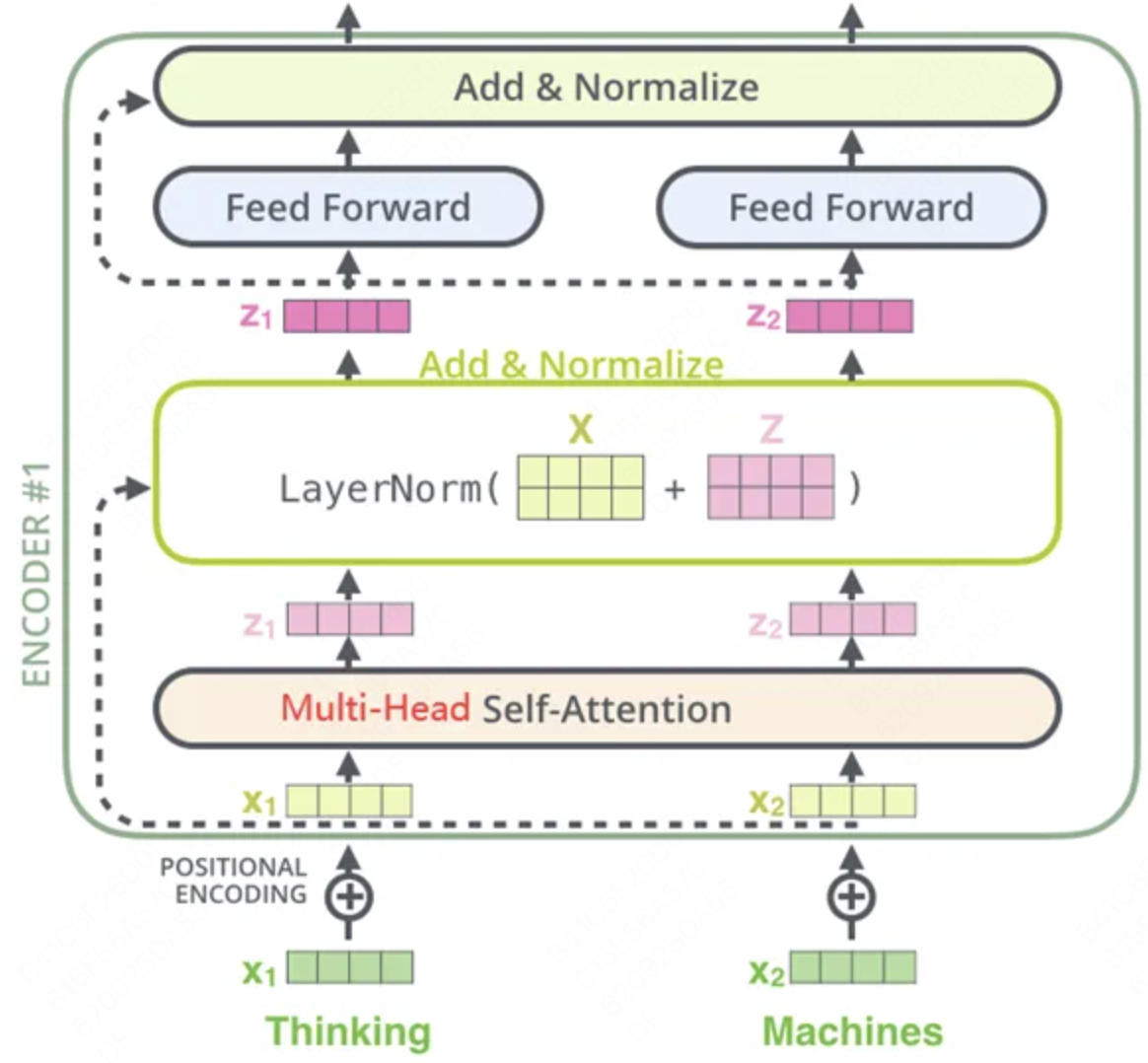
- Encoder 编码器:
- Transformer 中的编码器部分一共 6 个相同的编码器层组成。 每个编码器层都有两个子层,即多头自注意力层
(Multi-Head Attention)层和逐位置的前馈神经网络(Position-wise Feed-Forward Network)。在每个子层后面都有残差连接(图中的虚线)和层归一化(LayerNorm)操作,二者合起来称为Add&Norm操作。
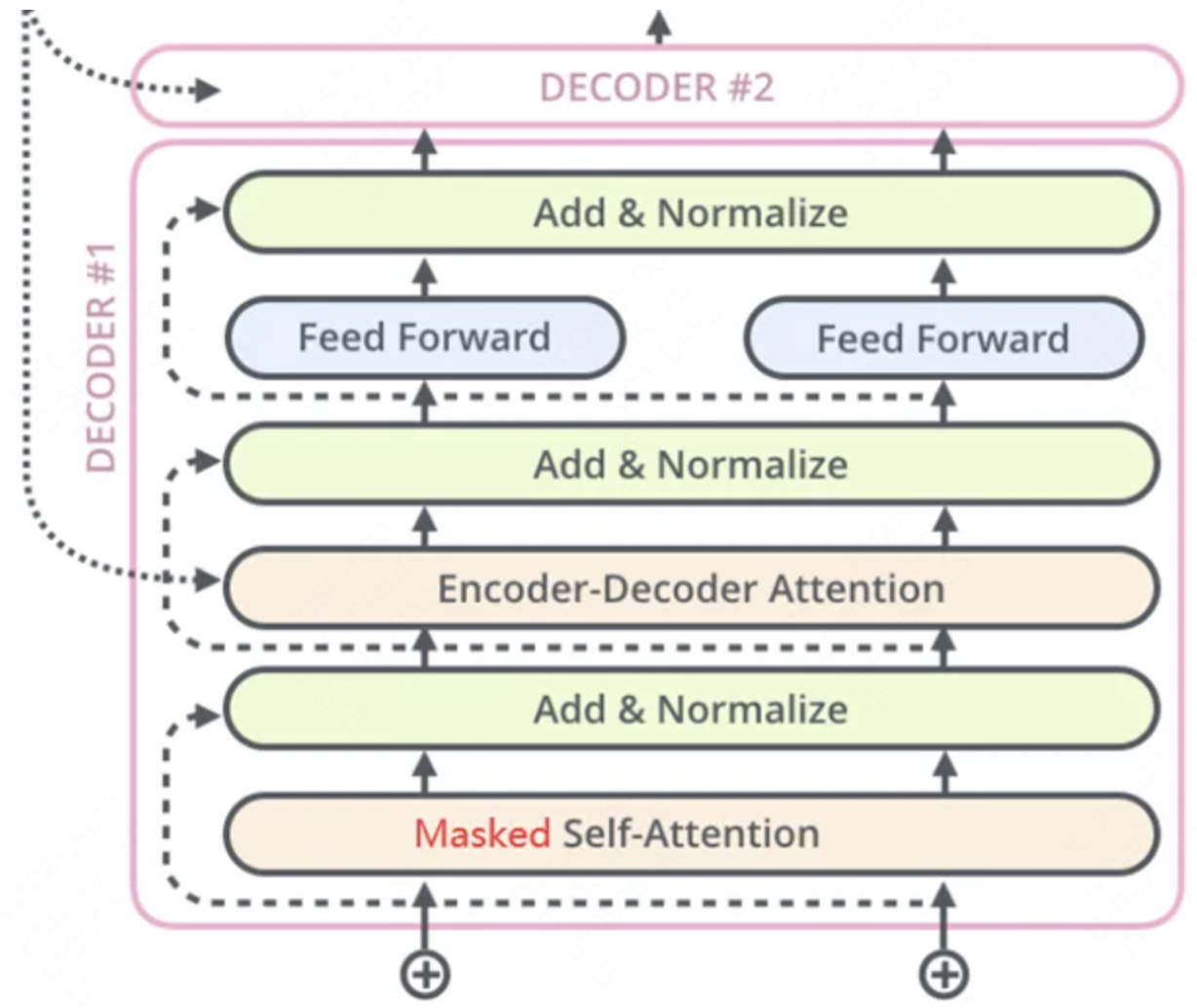
- Decoder 解码器:
- Transformer 中的解码器部分同样一共 6 个相同的解码器层组成。 每个解码器层都有三个子层,掩蔽自注意力层
(Masked Self-Attention)、Encoder-Decoder注意力层、逐位置的前馈神经网络。同样,在每个子层后面都有残差连接(图中的虚线)和层归一化(LayerNorm)操作,二者合起来称为Add&Norm操作。
2. Transformer 的原理
Multi-Head Attention(多头注意力):它允许模型同时关注来自不同位置的信息。通过分割原始的输入向量到多个头(head),每个头都能独立地学习不同的注意力权重,从而增强模型对输入序列中不同部分的关注能力。
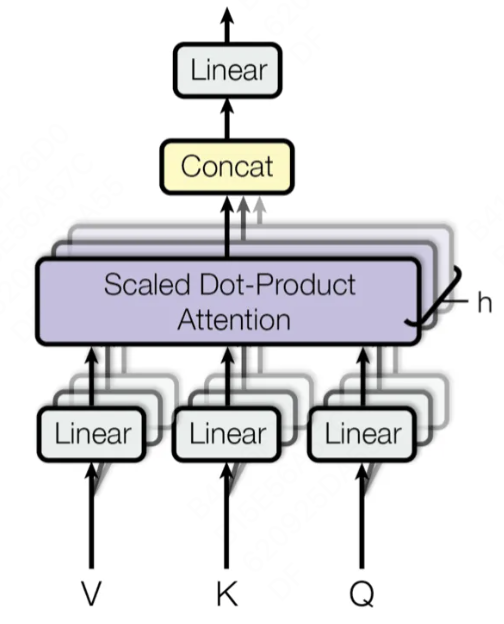
- 输入线性变换:对于输入的
Query(查询)、Key(键)和Value(值)向量,首先通过线性变换将它们映射到不同的子空间。这些线性变换的参数是模型需要学习的。 - 分割多头:经过线性变换后,
Query、Key和Value向量被分割成多个头。每个头都会独立地进行注意力计算。 - 缩放点积注意力:在每个头内部,使用缩放点积注意力来计算
Query和Key之间的注意力分数。这个分数决定了在生成输出时,模型应该关注Value向量的部分。 - 注意力权重应用:将计算出的注意力权重应用于
Value向量,得到加权的中间输出。这个过程可以理解为根据注意力权重对输入信息进行筛选和聚焦。 - 拼接和线性变换:将所有头的加权输出拼接在一起,然后通过一个线性变换得到最终的
Multi-Head Attention输出。
Scaled Dot-Product Attention(缩放点积注意力):它是 Transformer 模型中多头注意力机制的一个关键组成部分。
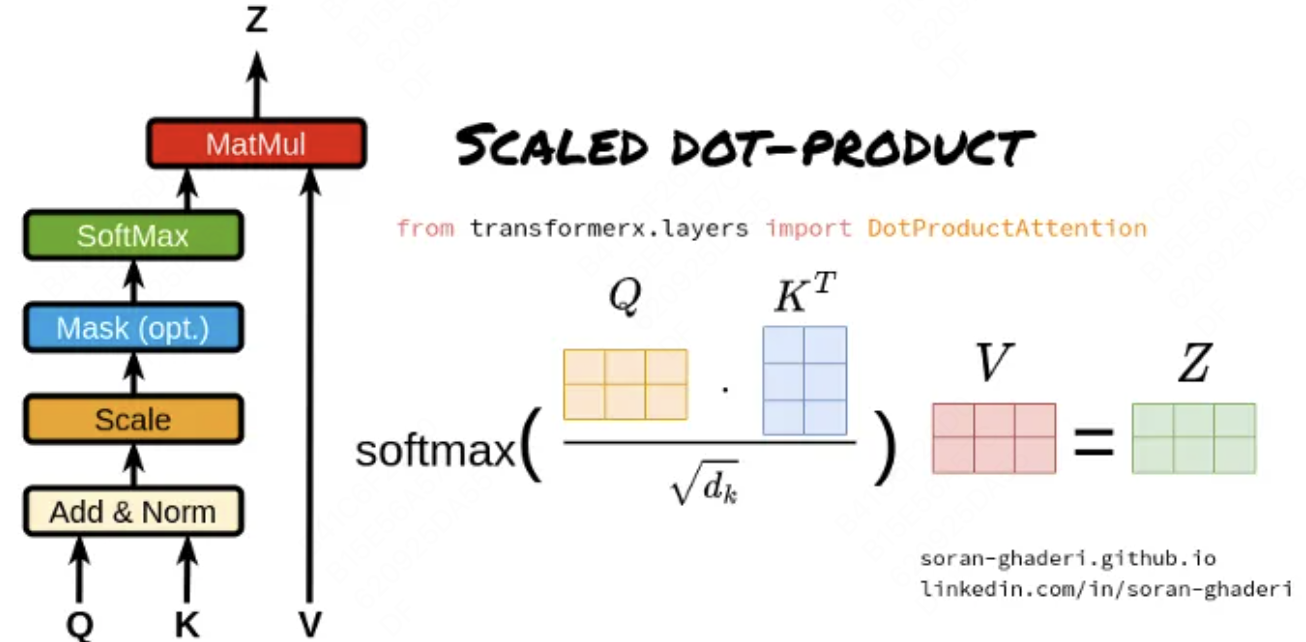
- Query、Key 和 Value 矩阵:
- Query 矩阵(Q):表示当前的关注点或信息需求,用于与
Key矩阵进行匹配。 - Key 矩阵(K):包含输入序列中各个位置的标识信息,用于被
Query矩阵查询匹配。 - Value 矩阵(V):存储了与
Key矩阵相对应的实际值或信息内容,当Query与某个Key匹配时,相应的Value将被用来计算输出。
- Query 矩阵(Q):表示当前的关注点或信息需求,用于与
- 点积计算:
- 通过计算
Query矩阵和Key矩阵之间的点积(即对应元素相乘后求和),来衡量Query与每个Key之间的相似度或匹配程度。
- 通过计算
- 缩放因子:
- 由于点积操作的结果可能非常大,尤其是在输入维度较高的情况下,这可能导致
softmax函数在计算注意力权重时进入饱和区。为了避免这个问题,缩放点积注意力引入了一个缩放因子,通常是输入维度的平方根。点积结果除以这个缩放因子,可以使得softmax函数的输入保持在一个合理的范围内。
- 由于点积操作的结果可能非常大,尤其是在输入维度较高的情况下,这可能导致
- Softmax 函数:
- 将缩放后的点积结果输入到
softmax函数中,计算每个Key相对于Query的注意力权重。Softmax函数将原始得分转换为概率分布,使得所有Key的注意力权重之和为1。
- 将缩放后的点积结果输入到
- 加权求和:
- 使用计算出的注意力权重对
Value矩阵进行加权求和,得到最终的输出。这个过程根据注意力权重的大小,将更多的关注放在与Query更匹配的Value上。
- 使用计算出的注意力权重对
3. Transformer 架构改进
BERT:BERT 是一种基于 Transformer 的预训练语言模型,它的最大创新之处在于引入了双向Transformer 编码器,这使得模型可以同时考虑输入序列的前后上下文信息。
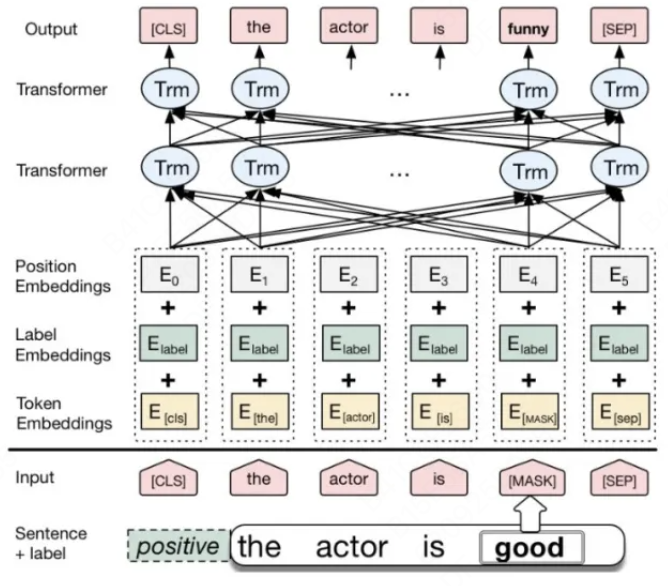
- 输入层(Embedding):
Token Embeddings:将单词或子词转换为固定维度的向量。Segment Embeddings:用于区分句子对中的不同句子。Position Embeddings:由于Transformer模型本身不具备处理序列顺序的能力,所以需要加入位置嵌入来提供序列中单词的位置信息。
- 编码层(Transformer Encoder):
BERT模型使用双向Transformer编码器进行编码。 - 输出层(Pre-trained Task-specific Layers):
MLM输出层:用于预测被掩码(masked)的单词。在训练阶段,模型会随机遮盖输入序列中的部分单词,并尝试根据上下文预测这些单词。NSP输出层:用于判断两个句子是否为连续的句子对。在训练阶段,模型会接收成对的句子作为输入,并尝试预测第二个句子是否是第一个句子的后续句子。
GPT:GPT 也是一种基于 Transformer 的预训练语言模型,它的最大创新之处在于使用了单向Transformer 编码器,这使得模型可以更好地捕捉输入序列的上下文信息。
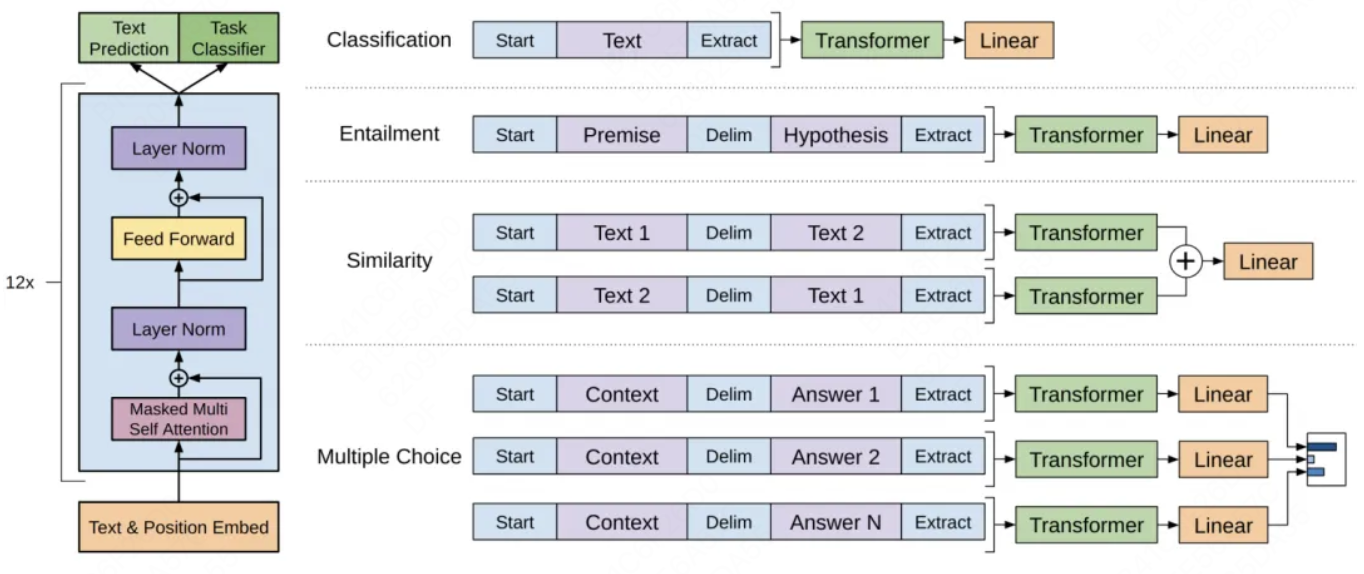
- 输入层(Input Embedding):
- 将输入的单词或符号转换为固定维度的向量表示。
- 可以包括词嵌入、位置嵌入等,以提供单词的语义信息和位置信息。
- 编码层(Transformer Encoder):
GPT模型使用单向Transformer编码器进行编码和生成。 - 输出层(Output Linear and Softmax):
- 线性输出层将最后一个
Transformer Decoder Block的输出转换为词汇表大小的向量。 Softmax函数将输出向量转换为概率分布,以便进行词汇选择或生成下一个单词。
- 线性输出层将最后一个
MCP
在当今 AI 飞速发展的时代,大型语言模型 (LLM) 如 Claude、ChatGPT 等已经在代码生成、内容创作等方面展现出惊人的能力。然而,这些强大的模型存在一个明显的局限性——它们通常与外部系统和工具隔离,无法直接访问或操作用户环境中的资源和工具。 而 Model Context Protocol (MCP) 的出现,正是为了解决这一问题。
Model Context Protocol (MCP):模型上下文协议 是由 Anthropic 公司推出的一个开放协议,它标准化了应用程序如何向大型语言模型 (LLM) 提供上下文和工具的方式。我们可以将 MCP 理解为 AI 应用的"USB-C 接口"——就像 USB-C 为各种设备提供了标准化的连接方式,MCP 为 AI 模型提供了与不同数据源和工具连接的标准化方式。 简单来说,MCP 可以做到以下事情:
读取和写入本地文件 查询数据库 执行命令行操作 控制浏览器 与第三方 API 交互
这极大地扩展了 AI 助手的能力边界,使其不再仅限于对话框内的文本交互。