组件封装篇
- 封装响应式面板分割组件,用于展示图像去雾前后对比图。该组件包含三部分:去雾前图像、去雾后图像以及拖拽线。拖拽线支持鼠标(
Web端)和触摸(移动端)进行移动(拖拽)操作,拖拽线左侧显示原图像右侧显示去雾后图像。封装后的组件引入后只需对两个插槽(before和after传递img即可)。为什么使用插 槽?为了让组件拥有一定的可拓展性,当传递的不是img数据时,让面板分割组件也可以正常使用。技术点:具名插槽 + 父子组件通信 +ref实例操作DOM对象 + 媒体查询。 - 封装
SVG组件,指定相应规则引入SVG。 - 自定义封装
Element-Plus的Message组件。 - 封装
Element-Plus的table(表格) 和pagiation(分页器)组件,实现表格与分页器的捆绑调用。
项目经历篇
- 图像去雾系统(
Vue3版 /React版 )
该系统集成了图像去雾的常用功能,包括:数据集管理、模型管理、图像去雾功能区、历史记录管理以及管理系统的登录 / 注册。
技术难点:
- 数据集图片的响应式瀑布流实现(非
grid布局)。系统为了更加生动的展示数据集图片内容,采用了瀑布流的形式进行展示。实现思路如下:规定容器开启相对定位,图片开启绝对定位并设置其固定宽度。根据每个图片的固定宽度 ,由ts将图片动态加载至容器中。计算当前屏幕尺寸下应该显示多少列与每列之间的间隔,开辟一个列数组,数组大小为列数,存放的数据为每列的最小高度。遍历所有图片,依次计算每张图片的位置(top、left)。图片纵坐标(top)位置摆放规则如下:每次以列数组中的最小值作为当前图片的纵坐标,根据该最小值找到对应索引项,更新数组中该列的最小高度值,计算图片的横坐标。图片横坐标(left)位置摆放规则如下:根据索引值let left = (index + 1) * info.space + index * imgWidth计算。遍历完所有图片后,获取列数组中的最大值作为整个瀑布流容器的高度。将上面的位置摆放函数绑定到每张图片加载完毕后执行img.onload = setPositions,监听窗口尺寸改变,重新排列图片,注意用防抖(避免重新排列操作过快重排次数过多导致页面卡顿)。 - 图像去雾功能区的放大镜、对比度、亮度调整功能。这三个功能均以原图与去雾后图片作为实例进行对比。
自定义指令篇(Vue3 版)
- 实现图片懒加载
创建自定义指令(v-lazy)应用到 img 标签中书写 <img v-lazy="图片地址" /> 即可。
实现步骤:
- 核心思想是使用
Vue的自定义指令,当图片出现在视口区域时触发图片懒加载,加载并显示该图片。其余未加载的图片显示默认加载图。 - 自定义指令其实就是一个函数,图片懒加载指令函数的类型是
Directive<HTMLImageElement, string>类型,图片懒加载指令函数接收两个参数:图片元素(el)和v-lazy的值(binding)。 - 使用
IntersectionObserver来侦听元素是否在窗口内,该函数需要传入一个回调函数。回调函数的形参是一个Entry数组,我们一般取该数组的第一项,即entrys[0],然后访问其intersectionRatio属性判断其是否大于0如果大于0则表示该元素已出现在视口区域内,此时我们需要把图片的src属性设置为binding.value即自定义指令后面跟的图片地址值,然后取消监听该元素。 - 通过
observer.observe(el)开启监听该元素。
示例代码:
const vLazy: Directive<HTMLImageElement, string> = {
async mounted(el, binding) {
// 加载默认占位图(带错误处理)
try {
const def = await import('../../assets/vue.svg')
el.src = def.default
} catch (err) {
console.error('[LazyLoad] 加载占位图失败:', err)
el.src = '/fallback-placeholder.png'
}
const observer = new IntersectionObserver((entries, observer) => {
entries.forEach(entry => {
if (entry.isIntersecting) {
const img = new Image()
img.src = binding.value
img.onload = () => {
el.src = binding.value
observer.unobserve(el)
}
img.onerror = () => {
el.src = '/error-placeholder.png'
observer.unobserve(el)
}
}
})
}, {
rootMargin: '0px 0px 200px 0px',
threshold: 1 // 完全可见触发
})
observer.observe(el)
el._lazyObserver = observer // 保存观察者引用
},
unmounted(el) {
// 组件卸载时取消观察
const observer = el._lazyObserver as IntersectionObserver
observer.unobserve(el)
delete el._lazyObserver
}
}TIP
IntersectionObserver 的缺点
无法精确到像素级检测(如检测元素是否完全进入视口)
无法直接获取元素进入视口的方向(需通过
boundingClientRect自行计算)jslet prevY = 0; const observer = new IntersectionObserver( (entries) => { const currentY = entries[0].boundingClientRect.y; const direction = currentY < prevY ? "down" : "up"; prevY = currentY; console.log(`滚动方向: ${direction}`); }, { threshold: 1 } );检测元素过多会有性能问题,因此,在被检测元素检测完毕后要及时的取消监控
Visibility检测局限:- 无法区分元素是否真正可见(可能被其他元素遮挡)
- 无法检测 CSS
opacity: 0或visibility: hidden的元素
跨域
iframe问题- 无法观察跨域
iframe内的元素 - 解决方案:在
iframe内部独立初始化观察器
- 无法观察跨域
- 实现按钮鉴权
按钮鉴权其实就是判断登录的用户是否有某个权限,如果有就显示该按钮,否则隐藏该按钮。
实现步骤:
- 核心思想是使用
Vue的自定义指令,当用户拥有某个权限时,显示相应权限的按钮。 - 本按钮鉴权自定义指令函数类型是
Directive<HTMLElement, string>,函数接收两个参数:按钮元素(el)和v-has-show的值(binding)。 - 判断用户的权限列表中是否包含有
v-has-show的值,如果没有则设置el.style.display = 'none'否则正常显示。
示例代码:
const vHasShow: Directive<HTMLElement, string> = (el, binding) => {
if (!permission.includes(userId + ":" + binding.value)) {
el.style.display = "none";
}
};- 自定义拖拽指令
给某个元素绑定自定义指令 v-move 该元素可以实现拖拽效果。
实现步骤:
- 核心思想是使用
Vue的自定义指令,监听鼠标的mousedown和mousemove事件。 - 本自定义拖拽指令函数类型是
Directive<any,void>如果没有返回值就定义为void,此时使用v-move指令时就无需传入数据了。 - 鼠标按下滑动、鼠标抬起事件清除。
示例代码:
<template>
<div v-move class="box">
<div class="header"></div>
<div>
事件一:小满在10w粉丝的时候cos女装
<br />
事件二:小满的QQ群有一只被群友称为洛佬的天才少年,有问题多问他,准没错
<br />
事件三:小满的QQ群号为:855139333
<br />
事件四:小满群里有个还在学HTML5的菜鸡小余,没事请多帮帮他
</div>
</div>
</template>
<script setup lang="ts">
import { Directive } from "vue";
const vMove: Directive<any, void> = {
//定义类型为Directive,如果没有返回值我们就定义为void
mounted(el: HTMLElement) {
let moveEl = el.firstElementChild as HTMLElement;
//TS写法:let moveEl:HTMLDivElement = el.firstElementChild as HTMLElement;
const mouseDown = (e: MouseEvent) => {
//mouseDown定义在这里
//鼠标点击物体那一刻相对于物体左侧边框的距离=点击时的位置相对于浏览器最左边的距离-物体左边框相对于浏览器最左边的距离
console.log(e.clientX, e.clientY, "-----起始", el.offsetLeft); //获取坐标值
let X = e.clientX - el.offsetLeft; //减去初始值
let Y = e.clientY - el.offsetTop;
const move = (e: MouseEvent) => {
el.style.left = e.clientX - X + "px";
el.style.top = e.clientY - Y + "px";
console.log(e.clientX, e.clientY, "---改变");
};
document.addEventListener("mousemove", move); //鼠标按下
document.addEventListener("mouseup", () => {
//鼠标抬起
document.removeEventListener("mousemove", move); //鼠标抬起就清除掉mousemove事件
});
};
//当我们对着header区域按下鼠标准备移动,绑定事件进行调用
moveEl.addEventListener("mousedown", mouseDown); //mouseDown事件定义在上方,mouseDown是参数一的一个事件类型,下方有事件类型大全
},
};
</script>
<style lang="less">
.box {
position: fixed;
left: 50%;
top: 50%;
transform: translate(-50%, -50%);
width: 600px;
height: 200px;
border: 1px solid #ccc;
.header {
height: 20px;
background: black;
cursor: move;
}
}
</style>自定义 Hooks 篇(Vue3 版)
- 监听元素宽高的实时变化
实际上主要是使用了一个新的 API ResizeObserver 来实现,兼容性一般。但是其可以监听元素的变化执行回调函数返回 contentRect 里面有变化之后的宽高。
import { App, defineComponent, onMounted } from "vue";
function useResize(
el: HTMLElement,
callback: (cr: DOMRectReadOnly, resize: ResizeObserver) => void
) {
let resize: ResizeObserver;
resize = new ResizeObserver((entries) => {
for (let entry of entries) {
const cr = entry.contentRect;
callback(cr, resize);
}
});
resize.observe(el);
}
const install = (app: App) => {
app.directive("resize", {
mounted(el, binding) {
useResize(el, binding.value);
},
});
};
useResize.install = install;
export default useResize;TIP
<div v-resize='回调函数'></div>
- 图片转
base64
使用 canvas 的 toDataURL 方法来返回导出的 base64 图片。
import { onMounted } from 'vue'
type Options = {
el: string
}
type Return = {
Baseurl: string | null
}
export default function (option: Options): Promise<Return> {//Promise的泛型什么类型自己定义
return new Promise((resolve) => {//套一个Promise,或者可以使用callback回去,就可以不使用promise(异步)了
onMounted(() => {
const file: HTMLImageElement = document.querySelector(option.el) as HTMLImageElement;//断言
file.onload = ():void => {//放在onload里面的东西会等其他所有内容加载完后再开始加载
resolve({
Baseurl: toBase64(file)//在套了一层Promise后进行返回
})
}
})
//转化为Base64图片的步骤
const toBase64 = (el: HTMLImageElement): string => {
const canvas: HTMLCanvasElement = document.createElement('canvas')//创建画布
const ctx = canvas.getContext('2d') as CanvasRenderingContext2D//创建画布
canvas.width = el.width//指定画步宽高
canvas.height = el.height
ctx.drawImage(el, 0, 0, canvas.width,canvas.height)//下方有drawImage参数详解
console.log(el.width);
return canvas.toDataURL('image/png')//返回导出图片。图片是啥自己替换
}
})
}
--------------------
//在其他导入此hook的使用方式
//先import引入
useBase64(el:"#img").then(res=>{
console.log(res.baseUrl)
})国际化篇
亮点:项目实现了静态信息国际化(Element 国际化)。
国际化具体实现方式:
- 首先要使用
npm / pnpm等包管理工具安装vue-i18n。
TIP
pnpm install vue-i18n
- 在
main.ts中导入i18n
//国际化 import i18n from './locales' app.use(i18n)- 新建
locales文件夹,并创建index.ts文件,编写国际化相关代码
import { createI18n } from "vue-i18n";
import zh from "./lang/zh-cn";
import en from "./lang/en";
//element语言包
import zhCn from "element-plus/dist/locale/zh-cn.mjs";
import English from "element-plus/dist/locale/en.mjs";
const messages = {
"zh-cn": {
el: zhCn,
...zh,
},
en: {
el: English,
...en,
},
};
const i18n = createI18n({
locale: localStorage.getItem("lang") || "zh-cn", // 初始化配置语言
messages,
});
export default i18n;- 在
locales文件夹中新建lang文件夹,里面存储各种语言的相关内容。
en.ts
export default {
login: {
slogan: "The most concise basic permission framework system.",
describe:
"Electron + Vue3 + element plus based front-end solutions in the background.",
signInTitle: "Sign in",
accountLogin: "Account sign in",
mobileLogin: "Mobile sign in",
rememberMe: "Remember me",
forgetPassword: "Forget password",
signIn: "Sign in",
signInOther: "Sign in with",
userPlaceholder: "user / phone / email",
userError: "Please input a user name",
PWPlaceholder: "Please input a password",
PWError: "Please input a password",
admin: "Administrator",
user: "User",
mobilePlaceholder: "Mobile",
mobileError: "Please input mobile",
smsPlaceholder: "SMS Code",
smsError: "Please input sms code",
smsGet: "Get SMS Code",
smsSent: "SMS sent to mobile number",
noAccount: "No account?",
createAccount: "Create a new account",
wechatLoginTitle: "QR code sign in",
wechatLoginMsg:
"Please use wechat to scan and log in | Auto scan after 3 seconds of simulation",
wechatLoginResult: "Scanned | Please click authorize login in the device",
},
user: {
dynamic: "Dynamic",
info: "User Info",
settings: "Settings",
nightmode: "night mode",
nightmode_msg:
"Suitable for low light environment,The current night mode is beta",
language: "language",
language_msg:
"Translation in progress,Temporarily translated the text of this view",
},
};zh-cn.ts
export default {
login: {
slogan: "最精简的基础权限框架系统",
describe: "基于Electron + Vue3 + Element-Plus 的中后台前端解决方案。",
signInTitle: "用户登录",
accountLogin: "账号登录",
mobileLogin: "手机号登录",
rememberMe: "24小时免登录",
forgetPassword: "忘记密码",
signIn: "登录",
signInOther: "其他登录方式",
userPlaceholder: "用户名 / 手机 / 邮箱",
userError: "请输入用户名",
PWPlaceholder: "请输入密码",
PWError: "请输入密码",
admin: "管理员",
user: "用户",
mobilePlaceholder: "手机号码",
mobileError: "111请输入手机号码",
smsPlaceholder: "短信验证码",
smsError: "请输入短信验证码",
smsGet: "获取验证码",
smsSent: "已发送短信至手机号码",
noAccount: "还没有账号?",
createAccount: "创建新账号",
wechatLoginTitle: "二维码登录",
wechatLoginMsg: "请使用微信扫一扫登录 | 模拟3秒后自动扫描",
wechatLoginResult: "已扫描 | 请在设备中点击授权登录",
},
user: {
dynamic: "近期动态",
info: "个人信息",
settings: "设置",
nightmode: "黑夜模式",
nightmode_msg: "适合光线较弱的环境,当前黑暗模式为beta版本",
language: "语言",
language_msg: "翻译进行中,暂翻译了本视图的文本",
},
};CAUTION
注意:这个文件夹里面的各种语言的信息要全部保持一致,不可以出现某个文件中含有其他文件中没有的信息,否则会出错。
- 使用方式
template:非绑定'插值表达式 $t('login.slogan') '
template:绑定<el-tab-pane :label="$t('login.accountLogin')">>js:const { proxy } = getCurrentInstance() as ComponentInternalInstance; proxy?.$t('login.mobileError')
CAUTION
注意:使用 js方式实现时要在 onBeforeMount 中使用 proxy ,否则会出现 $t is undefined 的情况!
TIP
有助于用户更顺利达成目标的建议性信息。
NOTE
强调用户在快速浏览文档时也不应忽略的重要信息。
IMPORTANT
对用户达成目标至关重要的信息。
WARNING
因为可能存在风险,所以需要用户立即关注的关键内容。
CAUTION
行为可能带来的负面影响。
大文件上传
总体流程
大文件上传是需要前端和后端配合来完成的一个操作。大文件上传一般包含:分片上传、妙传和断点续传。
分片上传指的是当上传比较大的文件时会出现上传时间比较久、中间一旦出错就需要重新上传等问题。这样就会给用户造成不好的体验,此时就需要用到分片上传。
秒传指的是当服务器上如果已经存在了某个 hash 值的文件, 此时用户再上传该文件,由于服务器获取到的 hash 值是一样的,因此我们就可以断定此时服务器上已经存在了该文件,直接给用户返回上传成功即可,给用户的感觉就像是实现了秒传。
断点续传 指的是当网络中断需要重新上传时,如果我们之前已经上传了一部分分片了,我们只需要再上传之前拿到的这部分分片,然后再过滤掉就可以避免重复上传这些分片了,也就是只需要上传那些上传失败的分片即可。
实现过程:前端上传完文件后,获取该文件信息,对该文件进行分片操作。
分片操作具体步骤:
TIP
定义一个常量,用于定义每个分片的大小。获取到上传的文件后,我们将该文件按着这个大小调用 Blob 对象的 slice 方法进行分片操作。并将每次的分片存储到一个数组中,返回该数组。这样,分片操作就完成了。
然后通过遍历分片操作后返回的数组,计算文件内容的 hash 值。hash 值的计算规则如下:
TIP
- 第一个切片和最后一个切片全部参与计算;
- 中间的这些切片,我们取开头、中间、结尾的前
2个字节参与计算即可。
之后,我们向后端发起一个是否需要上传的请求,这一步骤是为了判断服务器上有没有该 hash 值的文件,如果有,表示服务器上已经存在了该文件,因此就没有必要再上传一份了。前端直接提示用户 秒传 即可。如果不存在该文件,则要进行分片上传操作。在分片上传中我们要限制浏览器的并发请求次数,一般设置为 6 ,通过队列实现限制请求个数的并发上传操作。
TIP
为什么要限制并发请求数量?
我们以 1G 的文件来分析,假如每个分片的大小为 1M,那么总的分片数将会是 1024 个,如果我们同时发送这 1024 个分片,浏览器肯定处理不了,原因是切片文件过多,浏览器一次性创建了太多的请求。这是没有必要的,拿 chrome 浏览器来说,默认的并发数量只有 6,**过多的请求并不会提升上传速度,反而是给浏览器带来了巨大的负担。**因此,我们有必要限制前端请求个数。
怎么做呢,我们要创建最大并发数的请求,比如 6 个,那么同一时刻我们就允许浏览器只发送 6 个请求,其中一个请求有了返回的结果后我们再发起一个新的请求,依此类推,直至所有的请求发送完毕。
上传文件时一般还要用到 FormData 对象,需要将我们要传递的文件还有额外信息放到这个 FormData 对象里面。
TIP
表单数据以键值对的形式向服务器发送,这个过程是浏览器自动完成的。但是有时候,我们希望通过脚本完成过程,构造和编辑表单键值对,然后通过XMLHttpRequest.send()方法发送。浏览器原生提供了 FormData 对象来完成这项工作。
当所有的分片上传完成后,通知服务器可以进行合并操作。合并的时候需要从对应的文件夹中获取所有的切片,然后利用文件的读写操作,就可以实现文件的合并了。合并完成之后,我们将生成的文件以 hash 值命名存放到对应的位置就可以了。
前言
在日常开发中,文件上传是常见的操作之一。文件上传技术使得用户可以方便地将本地文件上传到 Web 服务器上,这在许多场景下都是必需的,比如网盘上传、头像上传等。
但是当我们需要上传比较大的文件的时候,容易碰到以下问题:
- 上传时间比较久
- 中间一旦出错就需要重新上传
- 一般服务端会对文件的大小进行限制
这两个问题会导致上传时候的用户体验是很不好的,针对存在的这些问题,我们可以通过分片上传来解决,这节课我们就在学习下什么是切片上传,以及怎么实现切片上传。
原理介绍
分片上传的原理就像是把一个大蛋糕切成小块一样。
首先,我们将要上传的大文件分成许多小块,每个小块大小相同,比如每块大小为 2MB。然后,我们逐个上传这些小块到服务器。上传的时候,可以同时上传多个小块,也可以一个一个地上传。上传每个小块后,服务器会保存这些小块,并记录它们的顺序和位置信息。
所有小块上传完成后,服务器会把这些小块按照正确的顺序拼接起来,还原成完整的大文件。最后,我们就成功地上传了整个大文件。
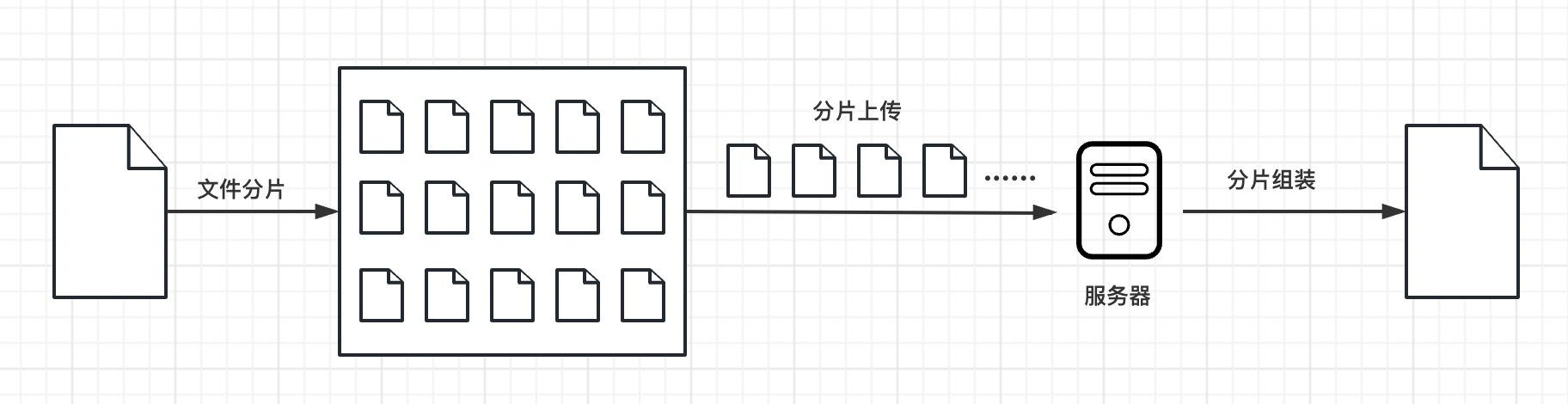
分片上传的好处在于它可以减少上传失败的风险。如果在上传过程中出现了问题,只需要重新上传出错的那个小块,而不需要重新上传整个大文件。
此外,分片上传还可以加快上传速度。因为我们可以同时上传多个小块,充分利用网络的带宽。这样就能够更快地完成文件的上传过程。
实现
项目搭建
要实现大文件上传,还需要后端的支持,所以我们就用 nodejs 来写后端代码。
前端:vue3 + vite
后端:express 框架,用到的工具包:multiparty、fs-extra、cors、body-parser、nodemon
读取文件
通过监听 input 的 change 事件,当选取了本地文件后,可以在回调函数中拿到对应的文件:
const handleUpload = (e: Event) => {
const files = (e.target as HTMLInputElement).files
if (!files) {
return;
}
// 读取选择的文件
console.log(files[0]);
}文件分片
文件分片的核心是用Blob 对象的 slice 方法,我们在上一步获取到选择的文件是一个File对象,它是继承于Blob,所以我们就可以用slice方法对文件进行分片,用法如下:
let blob = instanceOfBlob.slice([start [, end [, contentType]]]};start 和 end 代表 Blob 里的下标,表示被拷贝进新的 Blob 的字节的起始位置和结束位置。contentType 会给新的 Blob 赋予一个新的文档类型,在这里我们用不到。接下来就来使用slice方法来实现下对文件的分片。
const createFileChunks = (file: File) => {
const fileChunkList = [];
let cur = 0;
while (cur < file.size) {
fileChunkList.push({
file: file.slice(cur, cur + CHUNK_SIZE),
});
cur += CHUNK_SIZE; // CHUNK_SIZE为分片的大小
}
return fileChunkList;
};hash 计算
先来思考一个问题,在向服务器上传文件时,怎么去区分不同的文件呢?如果根据文件名去区分的话可以吗?
答案是不可以,因为文件名我们可以是随便修改的,所以不能根据文件名去区分。但是每一份文件的文件内容都不一样,我们可以根据文件的内容去区分,具体怎么做呢?
可以根据文件内容生产一个唯一的 hash 值,大家应该都见过用 webpack 打包出来的文件的文件名都有一串不一样的字符串,这个字符串就是根据文件的内容生成的 hash 值,文件内容变化,hash 值就会跟着发生变化。我们在这里,也可以用这个办法来区分不同的文件。而且通过这个办法,我们还可以实现秒传的功能,怎么做呢?
就是服务器在处理上传文件的请求的时候,要先判断下对应文件的 hash 值有没有记录,如果 A 和 B 先后上传一份内容相同的文件,所以这两份文件的 hash 值是一样的。当 A 上传的时候会根据文件内容生成一个对应的 hash 值,然后在服务器上就会有一个对应的文件,B 再上传的时候,服务器就会发现这个文件的 hash 值之前已经有记录了,说明之前已经上传过相同内容的文件了,所以就不用处理 B 的这个上传请求了,给用户的感觉就像是实现了秒传。
那么怎么计算文件的 hash 值呢?可以通过一个工具:spark-md5,所以我们得先安装它。
在上一步获取到了文件的所有切片,我们就可以用这些切片来算该文件的 hash 值,但是如果一个文件特别大,每个切片的所有内容都参与计算的话会很耗时间,所有我们可以采取以下策略:
- 第一个和最后一个切片的内容全部参与计算
- 中间剩余的切片我们分别在前面、后面和中间取 2 个字节参与计算
这样就既能保证所有的切片参与了计算,也能保证不耗费很长的时间
/**
* 计算文件的hash值,计算的时候并不是根据所用的切片的内容去计算的,那样会很耗时间,我们采取下面的策略去计算:
* 1. 第一个和最后一个切片的内容全部参与计算
* 2. 中间剩余的切片我们分别在前面、后面和中间取2个字节参与计算
* 这样做会节省计算hash的时间
*/
const calculateHash = async (fileChunks: Array<{file: Blob}>) => {
return new Promise(resolve => {
const spark = new sparkMD5.ArrayBuffer()
const chunks: Blob[] = []
// 遍历文件切片
fileChunks.forEach((chunk, index) => {
// 1. 第一个和最后一个切片的内容全部参与计算
if (index === 0 || index === fileChunks.length - 1) {
chunks.push(chunk.file)
} else {
// 2. 中间剩余的切片我们分别在前面、后面和中间取2个字节参与计算
// 前面的2字节
chunks.push(chunk.file.slice(0, 2))
// 中间的2字节
chunks.push(chunk.file.slice(CHUNK_SIZE / 2, CHUNK_SIZE / 2 + 2))
// 后面的2字节
chunks.push(chunk.file.slice(CHUNK_SIZE - 2, CHUNK_SIZE))
}
})
const reader = new FileReader()
reader.readAsArrayBuffer(new Blob(chunks))
reader.onload = (e: Event) => {
spark.append(e?.target?.result as ArrayBuffer)
resolve(spark.end())
}
})
}文件上传
前端实现
前面已经完成了上传的前置操作,接下来就来看下如何去上传这些切片。
我们以 1G 的文件来分析,假如每个分片的大小为 1M,那么总的分片数将会是 1024 个,如果我们同时发送这 1024 个分片,浏览器肯定处理不了,原因是切片文件过多,浏览器一次性创建了太多的请求。这是没有必要的,拿 chrome 浏览器来说,默认的并发数量只有 6,过多的请求并不会提升上传速度,反而是给浏览器带来了巨大的负担。因此,我们有必要限制前端请求个数。
怎么做呢,我们要创建最大并发数的请求,比如 6 个,那么同一时刻我们就允许浏览器只发送 6 个请求,其中一个请求有了返回的结果后我们再发起一个新的请求,依此类推,直至所有的请求发送完毕。
上传文件时一般还要用到 FormData 对象,需要将我们要传递的文件还有额外信息放到这个 FormData 对象里面。
const uploadChunks = async (fileChunks: Array<{ file: Blob }>) => {
const data = fileChunks.map(({ file }, index) => ({
fileHash: fileHash.value,
index,
chunkHash: `${fileHash.value}-${index}`,
chunk: file,
size: file.size,
}));
const formDatas = data.map(({ chunk, chunkHash }) => {
const formData = new FormData();
// 切片文件
formData.append("chunk", chunk);
// 切片文件hash
formData.append("chunkHash", chunkHash);
// 大文件的文件名
formData.append("fileName", fileName.value);
// 大文件hash
formData.append("fileHash", fileHash.value);
return formData;
});
let index = 0;
const max = 6; // 并发请求数量
const taskPool: any = []; // 请求队列
while (index < formDatas.length) {
const task = fetch("http://127.0.0.1:3000/upload", {
method: "POST",
body: formDatas[index],
});
task.then(() => {
taskPool.splice(taskPool.findIndex((item: any) => item === task));
});
taskPool.push(task);
if (taskPool.length === max) {
// 当请求队列中的请求数达到最大并行请求数的时候,得等之前的请求完成再循环下一个
await Promise.race(taskPool);
}
index++;
percentage.value = ((index / formDatas.length) * 100).toFixed(0);
}
await Promise.all(taskPool);
};后端实现
后端我们处理文件时需要用到 multiparty 这个工具,所以也是得先安装,然后再引入它。
我们在处理每个上传的分片的时候,应该先将它们临时存放到服务器的一个地方,方便我们合并的时候再去读取。为了区分不同文件的分片,我们就用文件对应的那个 hash 为文件夹的名称,将这个文件的所有分片放到这个文件夹中。
// 所有上传的文件存放到该目录下
const UPLOAD_DIR = path.resolve(__dirname, "uploads");
// 处理上传的分片
app.post("/upload", async (req, res) => {
const form = new multiparty.Form();
form.parse(req, async function (err, fields, files) {
if (err) {
res.status(401).json({
ok: false,
msg: "上传失败",
});
}
const chunkHash = fields["chunkHash"][0];
const fileName = fields["fileName"][0];
const fileHash = fields["fileHash"][0];
// 存储切片的临时文件夹
const chunkDir = path.resolve(UPLOAD_DIR, fileHash);
// 切片目录不存在,则创建切片目录
if (!fse.existsSync(chunkDir)) {
await fse.mkdirs(chunkDir);
}
const oldPath = files.chunk[0].path;
// 把文件切片移动到我们的切片文件夹中
await fse.move(oldPath, path.resolve(chunkDir, chunkHash));
res.status(200).json({
ok: true,
msg: "received file chunk",
});
});
});写完前后端代码后就可以来试下看看文件能不能实现切片的上传,如果没有错误的话,我们的 uploads 文件夹下应该就会多一个文件夹,这个文件夹里面就是存储的所有文件的分片了。
文件合并
上一步我们已经实现了将所有切片上传到服务器了,上传完成之后,我们就可以将所有的切片合并成一个完整的文件了,下面就一块来实现下。
前端实现
前端只需要向服务器发送一个合并的请求,并且为了区分要合并的文件,需要将文件的 hash 值给传过去
/**
* 发请求通知服务器,合并切片
*/
const mergeRequest = () => {
// 发送合并请求
fetch("http://127.0.0.1:3000/merge", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({
size: CHUNK_SIZE,
fileHash: fileHash.value,
fileName: fileName.value,
}),
})
.then((response) => response.json())
.then(() => {
alert("上传成功");
});
};后端实现
在之前已经可以将所有的切片上传到服务器并存储到对应的目录里面去了,合并的时候需要从对应的文件夹中获取所有的切片,然后利用文件的读写操作,就可以实现文件的合并了。合并完成之后,我们将生成的文件以 hash 值命名存放到对应的位置就可以了。
// 提取文件后缀名
const extractExt = (filename) => {
return filename.slice(filename.lastIndexOf("."), filename.length);
};
/**
* 读的内容写到writeStream中
*/
const pipeStream = (path, writeStream) => {
return new Promise((resolve, reject) => {
// 创建可读流
const readStream = fse.createReadStream(path);
readStream.on("end", async () => {
fse.unlinkSync(path);
resolve();
});
readStream.pipe(writeStream);
});
};
/**
* 合并文件夹中的切片,生成一个完整的文件
*/
async function mergeFileChunk(filePath, fileHash, size) {
const chunkDir = path.resolve(UPLOAD_DIR, fileHash);
const chunkPaths = await fse.readdir(chunkDir);
// 根据切片下标进行排序
// 否则直接读取目录的获得的顺序可能会错乱
chunkPaths.sort((a, b) => {
return a.split("-")[1] - b.split("-")[1];
});
const list = chunkPaths.map((chunkPath, index) => {
return pipeStream(
path.resolve(chunkDir, chunkPath),
fse.createWriteStream(filePath, {
start: index * size,
end: (index + 1) * size,
})
);
});
await Promise.all(list);
// 文件合并后删除保存切片的目录
fse.rmdirSync(chunkDir);
}
// 合并文件
app.post("/merge", async (req, res) => {
const { fileHash, fileName, size } = req.body;
const filePath = path.resolve(
UPLOAD_DIR,
`${fileHash}${extractExt(fileName)}`
);
// 如果大文件已经存在,则直接返回
if (fse.existsSync(filePath)) {
res.status(200).json({
ok: true,
msg: "合并成功",
});
return;
}
const chunkDir = path.resolve(UPLOAD_DIR, fileHash);
// 切片目录不存在,则无法合并切片,报异常
if (!fse.existsSync(chunkDir)) {
res.status(200).json({
ok: false,
msg: "合并失败,请重新上传",
});
return;
}
await mergeFileChunk(filePath, fileHash, size);
res.status(200).json({
ok: true,
msg: "合并成功",
});
});到这里,我们就已经实现了大文件的分片上传的基本功能了,但是我们没有考虑到如果上传相同的文件的情况,而且如果中间网络断了,我们就得重新上传所有的分片,这些情况在大文件上传中也都需要考虑到,下面,我们就来解决下这两个问题。
秒传&断点续传
我们在上面有提到,如果内容相同的文件进行 hash 计算时,对应的 hash 值应该是一样的,而且我们在服务器上给上传的文件命名的时候就是用对应的 hash 值命名的,所以在上传之前是不是可以加一个判断,如果有对应的这个文件,就不用再重复上传了,直接告诉用户上传成功,给用户的感觉就像是实现了秒传。接下来,就来看下如何实现的。
前端实现
前端在上传之前,需要将对应文件的 hash 值告诉服务器,看看服务器上有没有对应的这个文件,如果有,就直接返回,不执行上传分片的操作了。
/**
* 验证该文件是否需要上传,文件通过hash生成唯一,改名后也是不需要再上传的,也就相当于秒传
*/
const verifyUpload = async () => {
return fetch("http://127.0.0.1:3000/verify", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({
fileName: fileName.value,
fileHash: fileHash.value,
}),
})
.then((response) => response.json())
.then((data) => {
return data; // data中包含对应的表示服务器上有没有该文件的查询结果
});
};
// 点击上传事件
const handleUpload = async (e: Event) => {
// ...
// uploadedList已上传的切片的切片文件名称
const res = await verifyUpload();
const { shouldUpload } = res.data;
if (!shouldUpload) {
// 服务器上已经有该文件,不需要上传
alert("秒传:上传成功");
return;
}
// 服务器上不存在该文件,继续上传
uploadChunks(fileChunks);
};后端实现
因为我们在合并文件时,文件名时根据该文件的 hash 值命名的,所以只需要看看服务器上有没有对应的这个 hash 值的那个文件就可以判断了。
// 根据文件hash验证文件有没有上传过
app.post("/verify", async (req, res) => {
const { fileHash, fileName } = req.body;
const filePath = path.resolve(
UPLOAD_DIR,
`${fileHash}${extractExt(fileName)}`
);
if (fse.existsSync(filePath)) {
// 文件存在服务器中,不需要再上传了
res.status(200).json({
ok: true,
data: {
shouldUpload: false,
},
});
} else {
// 文件不在服务器中,就需要上传
res.status(200).json({
ok: true,
data: {
shouldUpload: true,
},
});
}
});完成上面的步骤后,当我们再上传相同的文件,即使改了文件名,也会提示我们秒传成功了,因为服务器上已经有对应的那个文件了。
上面我们解决了重复上传的文件,但是对于网络中断需要重新上传的问题没有解决,那该如何解决呢?
如果我们之前已经上传了一部分分片了,我们只需要再上传之前拿到这部分分片,然后再过滤掉是不是就可以避免去重复上传这些分片了,也就是只需要上传那些上传失败的分片,所以,再上传之前还得加一个判断。
前端实现
我们还是在那个 verify 的接口中去获取已经上传成功的分片,然后在上传分片前进行一个过滤
const uploadChunks = async (
fileChunks: Array<{ file: Blob }>,
uploadedList: Array<string>
) => {
const formDatas = fileChunks
.filter((chunk, index) => {
// 过滤服务器上已经有的切片
return !uploadedList.includes(`${fileHash.value}-${index}`);
})
.map(({ file }, index) => {
const formData = new FormData();
// 切片文件
formData.append("file", file);
// 切片文件hash
formData.append("chunkHash", `${fileHash.value}-${index}`);
// 大文件的文件名
formData.append("fileName", fileName.value);
// 大文件hash
formData.append("fileHash", fileHash.value);
return formData;
});
// ...
};后端实现
只需要在 /verify 这个接口中加上已经上传成功的所有切片的名称就可以,因为所有的切片都存放在以文件的 hash 值命名的那个文件夹,所以需要读取这个文件夹中所有的切片的名称就可以。
/**
* 返回已经上传切片名
* @param {*} fileHash
* @returns
*/
const createUploadedList = async (fileHash) => {
return fse.existsSync(path.resolve(UPLOAD_DIR, fileHash))
? await fse.readdir(path.resolve(UPLOAD_DIR, fileHash)) // 读取该文件夹下所有的文件的名称
: [];
};
// 根据文件hash验证文件有没有上传过
app.post("/verify", async (req, res) => {
const { fileHash, fileName } = req.body;
const filePath = path.resolve(
UPLOAD_DIR,
`${fileHash}${extractExt(fileName)}`
);
if (fse.existsSync(filePath)) {
// 文件存在服务器中,不需要再上传了
res.status(200).json({
ok: true,
data: {
shouldUpload: false,
},
});
} else {
// 文件不在服务器中,就需要上传,并且返回服务器上已经存在的切片
res.status(200).json({
ok: true,
data: {
shouldUpload: true,
uploadedList: await createUploadedList(fileHash),
},
});
}
});